


 En la serie de posts de Hardening de binarios hemos visto que muchas defensas vienen implantadas en los propios compiladores, pero ¿cómo se implementan? Tomando el caso de GCC, The GNU Compiler Collection, vamos a explicar la infraestructura general de GCC y en grandes rasgos, cómo funciona un compilador.
En la serie de posts de Hardening de binarios hemos visto que muchas defensas vienen implantadas en los propios compiladores, pero ¿cómo se implementan? Tomando el caso de GCC, The GNU Compiler Collection, vamos a explicar la infraestructura general de GCC y en grandes rasgos, cómo funciona un compilador.
Si hemos tenido una asignatura de Compiladores en nuestra vida, en muchos casos nos habrán simplificado el proceso de compilación diciéndonos que se divide en dos componentes, por un lado el front-end y por otro el back-end. El front-end es el encargado de parsear el código fuente y traducirlo a un lenguaje intermedio que el compilador entienda; finalmente en el back-end es donde se traduce ese lenguaje intermedio a ensamblador.
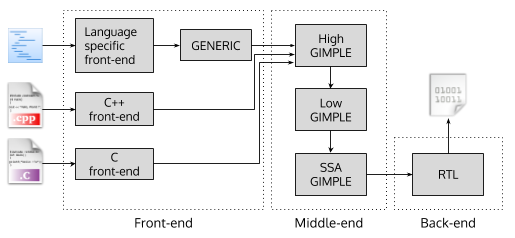
La realidad, en el caso de GCC, es algo más complicada, siendo la primera diferencia el número de componentes de los que se compone el compilador y la segunda que utiliza varios lenguajes intermedios. GCC se divide en tres componentes, el front-end, el middle-end y el back-end.
En el front-end se parsean los diferentes códigos fuente y se traducen a un lenguaje independiente de la máquina, GIMPLE. GIMPLE es un lenguaje basado en la representación de un código de tres direcciones (three-address code), donde todas las instrucciones tienen como máximo tres operandos. En esta fase es donde el compilador nos avisará si tenemos errores sintácticos en el programa a compilar. Cuando GCC compila C ó C++ la traducción pasa directamente de C/C++ a GIMPLE, si se trata de otro lenguaje, como FORTRAN, se traduce primero a GENERIC, otro lenguaje intermedio de GCC basado en árboles de sintaxis abstracta (ASTs de sus siglas inglesas), que a su vez es traducido a GIMPLE.
En el middle-end es donde se producen todas las optimizaciones, tanto intra-procedurales (propias de cada función) como inter-procedurales (que tienen en cuenta el estado de todas las funciones). En esta fase el compilador nos avisará si hemos cometido errores semánticos, si tenemos variables sin usar etc. En el middle-end se utilizan tres lenguajes diferentes, que son tres formas de GIMPLE: high-GIMPLE, low-GIMPLE y SSA-GIMPLE. En el high-GIMPLE los programas no tienen una representación de tres direcciones pura y en el low-GIMPLE sí. Finalmente el SSA-GIMPLE es un lenguaje intermedio también de tres direcciones, en el que se utiliza la forma de Static Single Assignment (SSA form) para hacer optimizaciones de forma más sencilla. La forma SSA tiene la particularidad de que las asignaciones “generan” una versión de la variable nueva, por ejemplo:
| a = 10; | a_1 = 10; |
| a = a + 1; | a_2 = a_1 + 1; |
| b = a; | b_1 = a_2; |
Las funciones típicas de este componente son la propagación de constantes y la optimización de tail-calls, además UBSan, VTV y ASan son implementadas en este componente. Finalmente, en el back-end se traduce el SSA-GIMPLE a un lenguaje dependiente de la máquina, RTL (Register Transfer Language) que ya se va pareciendo más a el lenguaje ensamblador, pero con la particularidad de que es funcional y deriva de Lisp.

