


Volvemos con un nuevo artículo sobre WEKA. Tras la introducción a Weka en la que vimos cómo preparar el entorno y utilizar algunas funciones básicas, y la segunda parte en la que tratamos de profundizar un poco más en esta herramienta, ahora toca hacer algunas pruebas clasificando textos. Y qué utilidad tiene esto de analizar texto se preguntará alguno, pues nos encontramos este tipo de tecnología en nuestro día a día, cuando recibimos sugerencias sobre productos que puedan interesarnos o, al contrario, dejamos de recibir ese tan molesto spam, para clasificar automáticamente documentos o cuando simplemente realizamos una consulta en nuestro buscador de internet preferido.
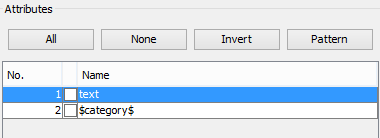 Para empezar a jugar, vamos a descargar un conjunto de datos que contiene una buena cantidad de muestras de correo electrónico legítimo y correo electrónico ilegítimo (spam): SpamAssassin. Si abrimos este conjunto de datos con WEKA e intentamos realizar alguna clasificación como la vista en los artículos anteriores, veremos que la gran mayoría de algoritmos no están disponibles (aparecen en un tono grisáceo). Si volvemos a la pestaña de pre-procesado y nos fijamos en los atributos del conjunto de datos, podemos observar que solo cuenta con dos: el contenido del e-mail, de tipo texto (text) y la clase, spam/legitimate ($category$). Si bien ya habíamos trabajado anteriormente con el tipo nominal (el tipo de la variable clase) el tipo texto es nuevo, y para poder trabajar con él debemos adaptarlo a las necesidades de los clasificadores. El motivo principal: la gran mayoría de algoritmos con los que vamos a realizar pruebas no “entienden” el texto, con lo que debemos “traducirlo” a variables numéricas.
Para empezar a jugar, vamos a descargar un conjunto de datos que contiene una buena cantidad de muestras de correo electrónico legítimo y correo electrónico ilegítimo (spam): SpamAssassin. Si abrimos este conjunto de datos con WEKA e intentamos realizar alguna clasificación como la vista en los artículos anteriores, veremos que la gran mayoría de algoritmos no están disponibles (aparecen en un tono grisáceo). Si volvemos a la pestaña de pre-procesado y nos fijamos en los atributos del conjunto de datos, podemos observar que solo cuenta con dos: el contenido del e-mail, de tipo texto (text) y la clase, spam/legitimate ($category$). Si bien ya habíamos trabajado anteriormente con el tipo nominal (el tipo de la variable clase) el tipo texto es nuevo, y para poder trabajar con él debemos adaptarlo a las necesidades de los clasificadores. El motivo principal: la gran mayoría de algoritmos con los que vamos a realizar pruebas no “entienden” el texto, con lo que debemos “traducirlo” a variables numéricas.
 Y aquí es donde entra el Modelo de espacio vectorial (del inglés, VSM), que se encarga de representar esas palabras que encontramos en el contenido textual en un espacio vectorial de modo que los algoritmos de aprendizaje automático de WEKA puedan trabajar con ellos. Para representar nuestros mails de esta forma, debemos ir al apartado de pre-procesado en WEKA y seleccionar el filtro “StringToWordVector” que podemos encontrar en: filters-unsupervised-attribute.
Y aquí es donde entra el Modelo de espacio vectorial (del inglés, VSM), que se encarga de representar esas palabras que encontramos en el contenido textual en un espacio vectorial de modo que los algoritmos de aprendizaje automático de WEKA puedan trabajar con ellos. Para representar nuestros mails de esta forma, debemos ir al apartado de pre-procesado en WEKA y seleccionar el filtro “StringToWordVector” que podemos encontrar en: filters-unsupervised-attribute.
Lo mejor que podemos hacer para ver las transformaciones es aplicar el filtro con las opciones por defecto, guardar el conjunto de datos transformado (añadiéndole el sufijo “_BOW” por ejemplo, del inglés Bag Of Words) y ver los resultados. Si abrimos el nuevo “Spam_Assassin_BOW” con un editor de textos, veremos que ya no tenemos solo 2 variables. Lo que hemos hecho es conservar la variable que contiene la categoría, el tipo de mensaje, y convertir la variable de tipo texto en todos los términos encontrados en el contenido de todos los mensajes del conjunto de datos. Si bajamos hasta la sección que contiene los datos (@data), podremos observar como cada e-mail se ha representado a través de parejas de números, correspondiendo el primero de ellos al número de atributo y el segundo a la aparición del mismo o no (1 o 0) en dicha instancia. Si bien de esta forma ya podemos representar ese texto de una forma matemática, la simple indicación de si un e-mail contiene o no un término no es un método muy preciso (ya que por ejemplo podría aparecer múltiples veces y no verse aquí reflejado). Así, accediendo a las opciones del filtro podremos incluir nuevas transformaciones que nos proporcionen un conjunto de datos más adecuado.

En primer lugar, nos encontramos con las transformaciones TF e IDF. Con la primera de ellas conseguimos la frecuencia de los términos en los documentos, es decir, la relevancia de cada palabra respecto al documento (al e-mail), en base a la extensión y número de apariciones. Con la segunda, frecuencia inversa de documento, obtenemos la relevancia de cada término respecto a la colección, es decir, si un término es representativo no solo para un documento sino para todo el conjunto.
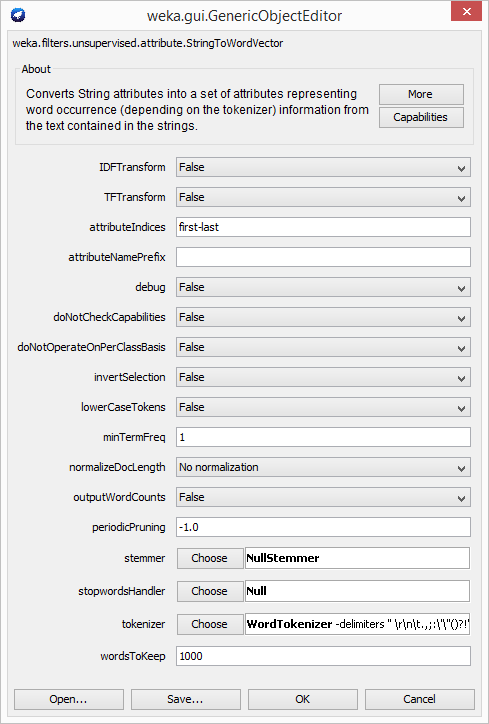 Juntando ambas transformaciones conseguimos una representación mucho más interesante para nuestro conjunto de datos. Probemos ahora a aplicar cada una de las combinaciones y guardemos los resultados (“Spam_Assassin_TF”, “Spam_Assassin_IDF” y “Spam_Assassin_TFIDF”) para después compararlos abriéndolos con un editor de texto. Si seguimos investigando las opciones nos encontramos con otras como los atributos sobre los que queremos operar (attributeIndices), si queremos obtener las frecuencias de los términos por clase o respecto a toda la colección (doNotOperateOnPerClassBasis), si queremos reducir los términos a su raíz (stemmer), las palabras que queremos eliminar por carecer de valor semántico (stopWords), la forma de obtener los términos (tokenizer) o las palabras a quedarse por cada clase (wordsToKeep). Para obtener más información podemos pinchar en la opción “More”, que nos ofrecerá una descripción de cada una de las opciones disponibles.
Juntando ambas transformaciones conseguimos una representación mucho más interesante para nuestro conjunto de datos. Probemos ahora a aplicar cada una de las combinaciones y guardemos los resultados (“Spam_Assassin_TF”, “Spam_Assassin_IDF” y “Spam_Assassin_TFIDF”) para después compararlos abriéndolos con un editor de texto. Si seguimos investigando las opciones nos encontramos con otras como los atributos sobre los que queremos operar (attributeIndices), si queremos obtener las frecuencias de los términos por clase o respecto a toda la colección (doNotOperateOnPerClassBasis), si queremos reducir los términos a su raíz (stemmer), las palabras que queremos eliminar por carecer de valor semántico (stopWords), la forma de obtener los términos (tokenizer) o las palabras a quedarse por cada clase (wordsToKeep). Para obtener más información podemos pinchar en la opción “More”, que nos ofrecerá una descripción de cada una de las opciones disponibles.
Ahora que ya podemos dar por finalizada la representación de nuestro conjunto de datos de forma que los algoritmos de clasificación de WEKA puedan entenderlos, podemos pasar a la pestaña “Classify”, probar algunos de los algoritmos y valorar su funcionamiento siguiendo las medidas de calidad deseadas. No nos olvidemos por cierto de seleccionar el atributo clase antes de iniciar la clasificación (en la misma sección de clasificación) después de seleccionar el algoritmo deseado, o bien de reordenar los atributos como vimos en entradas anteriores. Y con esto ya tenemos el conocimiento básico para crear un clasificador de documentos.
Ahora solo queda decidir a cuál de las múltiples áreas que existen actualmente queremos aplicar estos métodos y, después, descubrir la forma de conseguir la mayor cantidad de datos (a poder ser de forma legal) para entrenarlos y conseguir así el mejor funcionamiento posible. Porque recordad, el conocimiento es poder y hoy en día ese conocimiento se fundamenta en nuestros datos.

