


Después de introducción a Weka que vimos hace unas semanas, en el post de hoy trataremos de profundizar un poco más en esta herramienta. Para empezar, vamos a descargar un conjunto de datos nuevo con características sobre la producción vinícola: wine.arff. Para visualizar su contenido, podemos abrirlo directamente y seleccionar Weka como herramienta predeterminada o dentro de la sección Explorer y pestaña Preprocess, abrir el fichero.
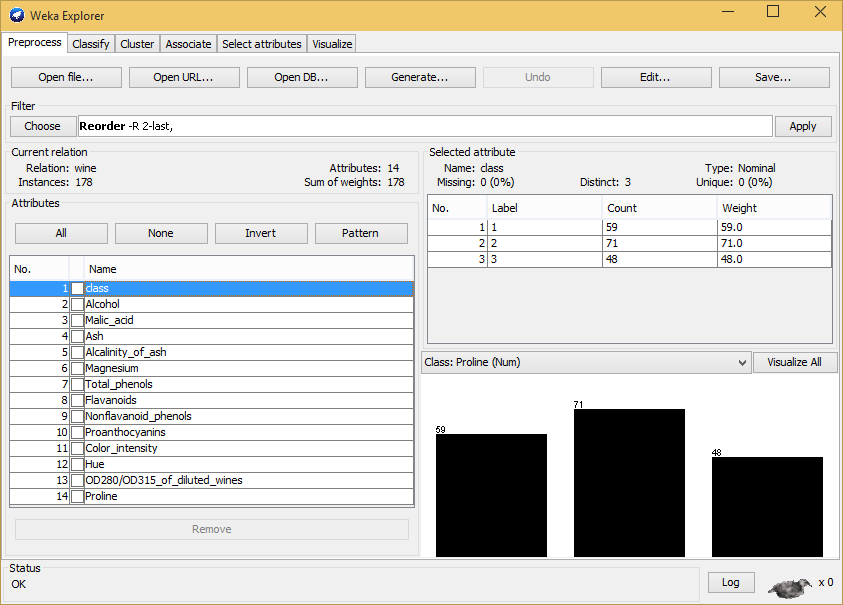
Si repasamos los atributos del dataset, vemos que aparece como primero de ellos “class”, la clase de cada uno de los elementos que lo componen. En este caso tenemos las clases 1, 2 y 3, correspondientes a diferentes categorías de vino. Por defecto, Weka entiende que el último atributo será la clase de cada uno de esos elementos, por lo que lo primero que vamos a hacer es jugar un poco con los filtros para transformar nuestros datos. Abrimos entonces la sección Filter dentro de la misma pestaña Preprocess. Ahí vemos una gran cantidad de opciones, veremos algunas de ellas en ésta y en próximas entregas. Ahora seleccionamos unsupervised-attribute-REORDER. Este filtro nos permite ordenar nuestros atributos. Una vez seleccionado pinchamos en el nombre del propio filtro y nos aparecerá una ventana con opciones.
Cambiamos los parámetros de attributeIndices por “2-last,first” y pulsamos OK. Después seleccionamos Apply. Esos parámetros nos permiten reordenar los atributos a nuestro antojo de una forma sencilla (nótese que estos cambios no se han guardado en el fichero del conjunto de datos, están en memoria, si queremos conservarlos, deberemos guardarlos mediante la opción Save). Si el resultado del filtro aplicado no termina de convencernos, siempre podemos volver al estado anterior mediante la opción Undo. Probemos una clasificación rápida (e.g., Naive Bayes) y veamos los resultados. Son buenos pero siempre se puede intentar mejorarlos tratando un poco más nuestro conjunto de datos.
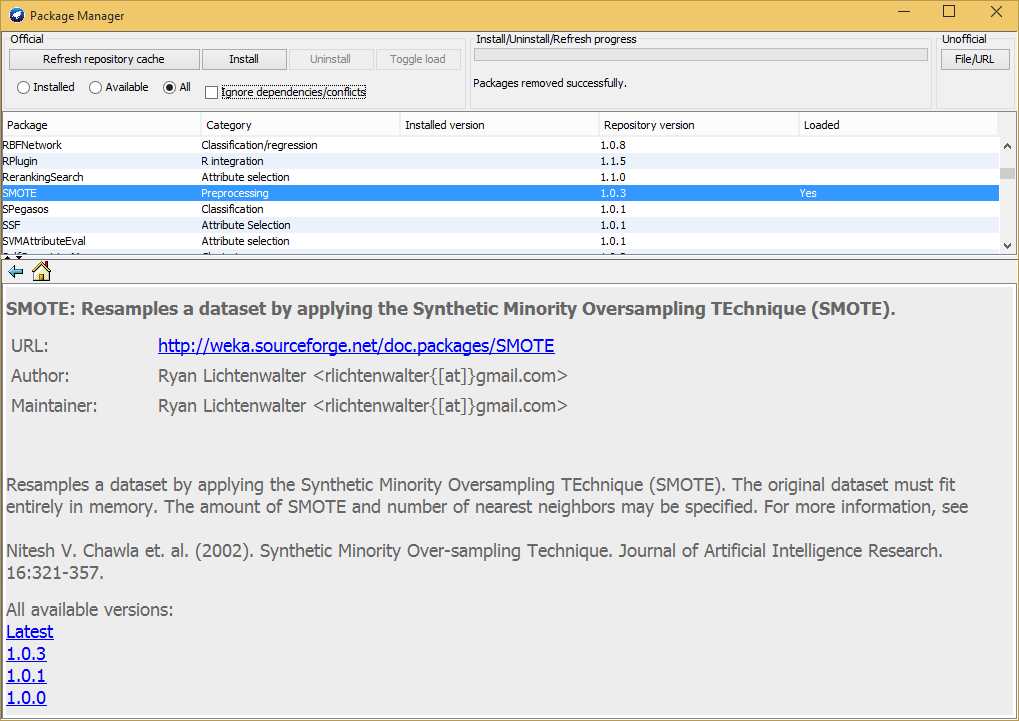 Antes de seguir viendo filtros, vamos a descubrir una nueva funcionalidad disponible en Weka desde la versión 3.7, el gestor de paquetes. Cerramos la ventana del Explorer y dentro de la ventana inicial seleccionamos Tools-Package Manager. Aquí tenemos un listado de módulos que ofrecen nuevas opciones a las ya de por si extensas disponibles por defecto. Busquemos por ejemplo el paquete SMOTE dentro de la categoría Preprocessing y lo instalamos. Este filtro genera nuevas muestras de forma sintética, lo que ayudará en los casos en los que el número de elementos empleados para generar el modelo (el “conocimiento”) no es demasiado extenso, como puede ser el caso de nuestro dataset de vinos. Porque recordemos, al igual que en la vida real, cuanto mayor es nuestro conocimiento mayor es nuestra capacidad de identificar elementos, de clasificarlos.
Antes de seguir viendo filtros, vamos a descubrir una nueva funcionalidad disponible en Weka desde la versión 3.7, el gestor de paquetes. Cerramos la ventana del Explorer y dentro de la ventana inicial seleccionamos Tools-Package Manager. Aquí tenemos un listado de módulos que ofrecen nuevas opciones a las ya de por si extensas disponibles por defecto. Busquemos por ejemplo el paquete SMOTE dentro de la categoría Preprocessing y lo instalamos. Este filtro genera nuevas muestras de forma sintética, lo que ayudará en los casos en los que el número de elementos empleados para generar el modelo (el “conocimiento”) no es demasiado extenso, como puede ser el caso de nuestro dataset de vinos. Porque recordemos, al igual que en la vida real, cuanto mayor es nuestro conocimiento mayor es nuestra capacidad de identificar elementos, de clasificarlos.
Volvemos al explorador y buscamos el filtro supervised-instance-SMOTE. Sin cambiar los parámetros de configuración del filtro, lo aplicamos. Vemos que pasamos de 178 instancias (elementos) a 226. Si probamos a clasificar de nuevo con el mismo algoritmo de antes, se puede apreciar una ligera mejoría en los resultados.
Y con ésto terminamos por hoy. Próximamente veremos cómo aplicar este tipo de algoritmos a textos, porque si alguno ha encontrado o generado un conjunto de datos con, por ejemplo, contenido de webs, tweets o e-mails habrá observado que no era posible realizar la clasificación siguiendo los pasos vistos hasta ahora. Con ello empezaremos a adentrarnos en el extenso mundo de la clasificación automática de textos, una de las bases para multitud de herramientas que usamos día a día.

