


Precisión y cobertura son dos de las medidas más utilizadas para evaluar el comportamiento de un algoritmo de clasificación. Ambas miden lo bien que se ha comportado el algoritmo, pero desde un punto de vista diferente. En esta entrada daremos una idea de estas medidas a partir de un ejemplo ilustrativo.
Un cirujano particular
Para explicar estas medidas me gusta usar como ejemplo a un cirujano (en el papel de algoritmo de clasificación) extrayendo células cancerígenas. Al finalizar la operación el cirujano habrá extraído las células cancerígenas y dejado en el cuerpo las no cancerígenas. Pero como la perfección es imposible, como en todos los ámbitos, es posible que el cirujano haya extraído ciertas células no debiera y que se haya dejado otras que debió extraer. En este supuesto, llamamos precisión al porcentaje de células cancerígenas de entre las células extraídas, y llamamos cobertura al porcentaje de células extraídas de entre las células cancerígenas.
Un poco trabalenguas, ¿no? En nuestro ejemplo, si el cáncer está localizado en un área vital, el cirujano extraerá sólo células cancerígenas y no se arriesgará a eliminar células sanas por temor a dañar la zona, con lo cual se dejará bastantes células cancerígenas. En este caso el cirujano tendrá alta precisión pero baja cobertura. Si por el contrario, la zona en la que está localizado el cáncer no es de riesgo, muy seguramente nuestro cirujano particular se arriesgará a extraer todas las células cancerígenas, llevándose con sí células sanas. En este caso, tendrá muy buena cobertura a costa de sacrificar la precisión.
Lo ideal sería un algoritmo con valores altos tanto de precisión y de cobertura, pero suele ser habitual, como en este ejemplo, que para ganar en una medida se suele tener que sacrificar la otra. Así, en general como medidas de calidad de algoritmo se suelen dar medidas que engloban el resultado de estas dos, como F1-score o el coeficiente de correlación de Matthews (o coeficiente phi).
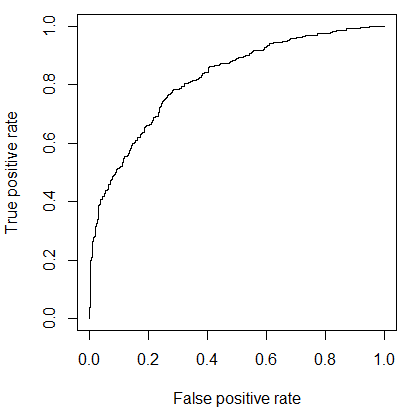 AUC – Área bajo la curva ROC
AUC – Área bajo la curva ROC
Pero de todas estas medidas que aglutinan precisión y cobertura, la que destaca por encima de todas, es el área bajo la curva ROC (AUC, por sus siglas en inglés). Para explicar esta medida hemos de modificar sutilmente el ejemplo. Ahora no queremos evaluar la calidad del cirujano en una operación, sino que queremos evaluar la calidad de nuestro “cirujano configurable”. Configurable porque dependiendo de qué cáncer esté extirpando, se arriesgará más a extraer más células, o será más conservador. Aún así habrá mejores cirujanos que otros. La curva ROC representa los pares precisión-cobertura, codificados como ratios de verdaderos positivos y falsos positivos, según vamos variando la configuración. Una curva más alta indicará mejores valores de precisión a un mismo valor de cobertura. Así pues, AUC medirá el comportamiento global del cirujano en sus diferentes configuraciones.

