


 Comenzaremos con lo básico, la instalación y familiarización con la herramienta, y un ejemplo sencillo para ver sus posibilidades. Pasemos entonces a descargar WEKA desde la web de la Universidad de Waikato, en Nueva Zelanda. Dentro de su sección de descargas, buscaremos la versión para desarrolladores (developers) y así tendremos la versión más actualizada (3-7).
Comenzaremos con lo básico, la instalación y familiarización con la herramienta, y un ejemplo sencillo para ver sus posibilidades. Pasemos entonces a descargar WEKA desde la web de la Universidad de Waikato, en Nueva Zelanda. Dentro de su sección de descargas, buscaremos la versión para desarrolladores (developers) y así tendremos la versión más actualizada (3-7).
Una vez descargado e instalado, antes de comenzar a usarlo, deberemos buscar en el directorio de instalación de WEKA el fichero “RunWeka.ini” y modificar la línea “maxheap=” para aumentar la capacidad de la máquina virtual de Java y posibilitar así trabajar con volúmenes de datos más importantes. Un buen valor podría ser, siempre dependiendo de la cantidad de memoria RAM disponible, 4 gigas, quedando la línea entonces como: “maxheap=4G”. Ahora sí, ejecutamos WEKA. Para empezar, tenemos dos opciones de ejecución, “con” y “sin” consola. El primero nos ofrece constante feedback sobre lo que vayamos haciendo con la herramienta y puede ser de gran utilidad cuando nos encontremos con algún error durante el análisis de nuestros datos. Una vez iniciado WEKA, nos encontramos con varias opciones.La opción Explorer nos ofrece la posibilidad de trabajar con nuestro conjunto de datos, visualizarlo y pre-procesarlo, y por supuesto también realizar análisis y clasificaciones. La opción Experimenter nos permite, una vez tenemos nuestros datos preparados, realizar análisis de forma más automatizada/masiva. KnowledgeFlow es una herramienta que nos ayuda a crear un flujo de análisis de forma muy visual, arrastrando elementos al espacio de trabajo. Por último SimpleCLI nos permite realizar el tratamiento y análisis desde consola. En este artículo, nos limitaremos a conocer un poco la herramienta Explorer, vamos con ello.
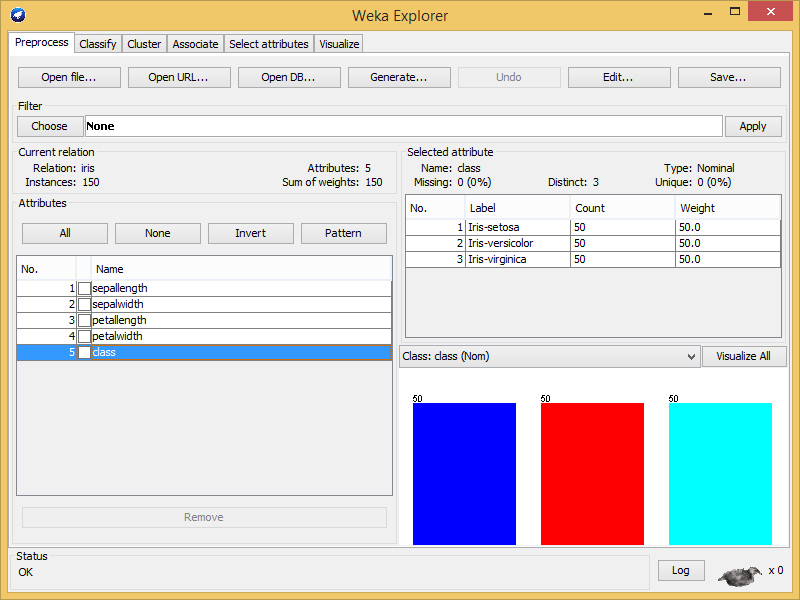 Como vemos, nos encontramos diversas pestañas con una serie de opciones para tratamiento (Preprocess), clasificación (Classify-Cluster-Associate-Select attributes) y visualización de datos (Visualize). Por el momento vemos que la mayoría de opciones se encuentran desactivadas, el motivo, necesitamos cargar un conjunto de datos. Uno clásico para pruebas en WEKA es el de Iris, pero podemos escoger cualquiera o crear uno nosotros mismos en alguno de los formatos soportados (entre los que se incluye por ejemplo el formato csv). Si abrimos alguno de los ficheros con formato ARFF (específico de WEKA), podemos observar una primera sección de atributos, definidos mediante “@ATTRIBUTE”, y la sección de los datos propiamente dichos, delimitada por “@DATA”. Cada una de las líneas de la sección de datos (e.g., “5.1,3.5,1.4,0.2,Iris-setosa”) nos indican el valor tomado por cada uno de los atributos, siendo en este caso el último la clase de Iris de esa muestra.
Como vemos, nos encontramos diversas pestañas con una serie de opciones para tratamiento (Preprocess), clasificación (Classify-Cluster-Associate-Select attributes) y visualización de datos (Visualize). Por el momento vemos que la mayoría de opciones se encuentran desactivadas, el motivo, necesitamos cargar un conjunto de datos. Uno clásico para pruebas en WEKA es el de Iris, pero podemos escoger cualquiera o crear uno nosotros mismos en alguno de los formatos soportados (entre los que se incluye por ejemplo el formato csv). Si abrimos alguno de los ficheros con formato ARFF (específico de WEKA), podemos observar una primera sección de atributos, definidos mediante “@ATTRIBUTE”, y la sección de los datos propiamente dichos, delimitada por “@DATA”. Cada una de las líneas de la sección de datos (e.g., “5.1,3.5,1.4,0.2,Iris-setosa”) nos indican el valor tomado por cada uno de los atributos, siendo en este caso el último la clase de Iris de esa muestra.
Ahora sí, una vez cargado el conjunto de datos en WEKA, se nos activan todas las opciones y podemos comenzar a jugar con ellos. En la parte izquierda, podemos ver los atributos y si seleccionamos alguno de ellos veremos en la derecha los valores que toman. Por ejemplo, si seleccionamos el atributo “class” WEKA nos mostrará los diferentes tipos de Iris que componen el conjunto de datos: Iris-setosa, Iris-versicolor-Iris-virginica (en este caso con 50 instancias de cada una). En la parte izquierda, podemos ver los atributos y si seleccionamos alguno de ellos veremos en la derecha los valores que toman. Por ejemplo, si seleccionamos el atributo “class” WEKA nos mostrará los diferentes tipos de Iris que componen el conjunto de datos: Iris-setosa, Iris-versicolor-Iris-virginica (en este caso con 50 instancias de cada una). Una opción muy interesante en esta sección es la de Filter, que nos permitirá pre-procesar el conjunto de datos, eliminando atributos, ordenándolos, realizando transformaciones de los datos o, incluso, generando muestras de forma sintética. En próximas entradas iremos analizando estas opciones con más detalle para ver las inmensas posibilidades que ofrecen. Por el momento, y para ir acabando por hoy, pasemos a la pestaña de clasificación.
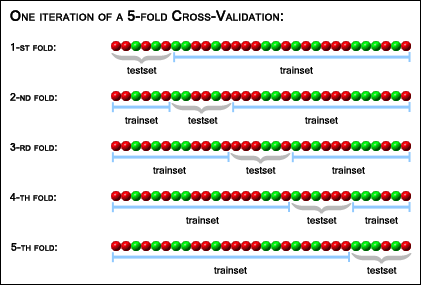
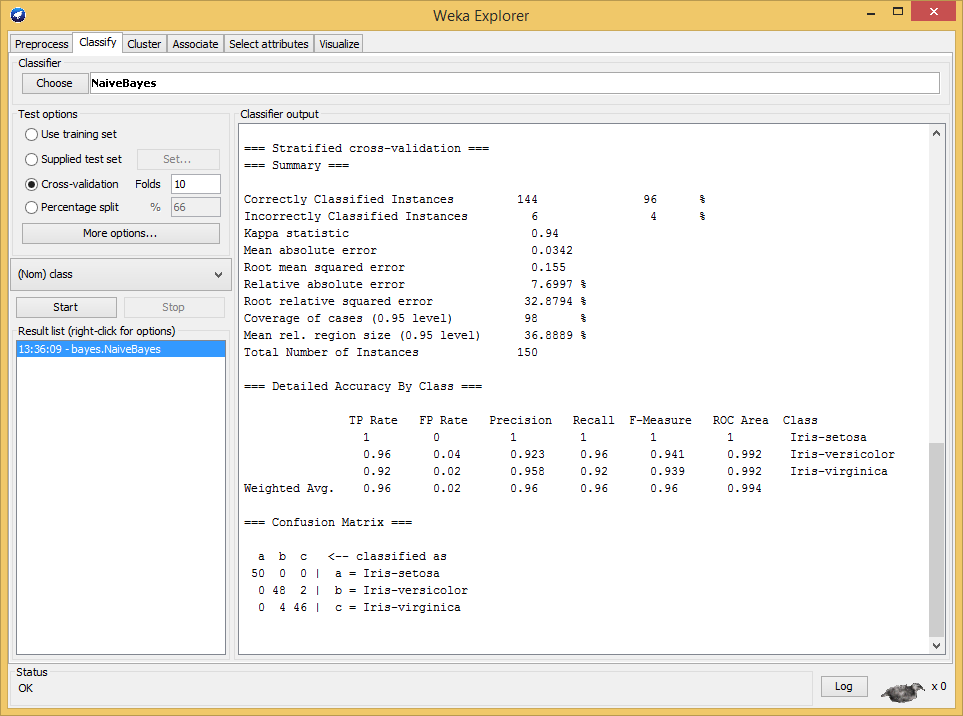 Aquí nos encontramos en primer lugar con la selección del clasificador (Classifier), donde podremos elegir qué algoritmo será el que determine el valor del atributo que queremos clasificar, en este caso “class”, la clase de Iris. Podemos observar que algunos algoritmos están desactivados, esto se debe al tipo de datos que tenemos cargados (también en próximas entregas, veremos con más detalle las limitaciones que tienen algunos algoritmos de clasificación y cómo solucionarlas). Por último, dentro de las opciones de prueba (Test options) nos encontramos con diversas posibilidades de cara a evaluar el funcionamiento de cada uno de los algoritmos que probemos. Por defecto tenemos seleccionada la validación cruzada (Cross-validation) con 10 folds. Este método divide el conjunto de datos en X subconjuntos, empleando X-1 para entrenar y 1 para comprobar, y realiza X iteraciones (siendo X el número de folds) este proceso.
Aquí nos encontramos en primer lugar con la selección del clasificador (Classifier), donde podremos elegir qué algoritmo será el que determine el valor del atributo que queremos clasificar, en este caso “class”, la clase de Iris. Podemos observar que algunos algoritmos están desactivados, esto se debe al tipo de datos que tenemos cargados (también en próximas entregas, veremos con más detalle las limitaciones que tienen algunos algoritmos de clasificación y cómo solucionarlas). Por último, dentro de las opciones de prueba (Test options) nos encontramos con diversas posibilidades de cara a evaluar el funcionamiento de cada uno de los algoritmos que probemos. Por defecto tenemos seleccionada la validación cruzada (Cross-validation) con 10 folds. Este método divide el conjunto de datos en X subconjuntos, empleando X-1 para entrenar y 1 para comprobar, y realiza X iteraciones (siendo X el número de folds) este proceso.
Cuando se habla de entrenar y testear, muy resumido, los algoritmos analizan las características (atributos) del conjunto de entrenamiento y con eso generan los modelos de clasificación (el “conocimiento”) para después pasar a clasificar las muestras del conjunto de testeo en base a sus características. Ya que todo el conjunto de datos que estamos probando es conocido, es decir, conocemos la clase de Iris de cada una de las muestras, cuando el algoritmo termina de clasificar podemos comprobar si el resultado ha sido correcto. Esto nos indicará lo bien que lo hace cada uno de ellos y así decidir cuál será interesante utilizar cuando queramos emplearlo para clasificar muestras que son realmente desconocidas.
Pasemos entonces a hacer una prueba rápida. Seleccionamos dentro de los clasificadores NaiveBayes, dentro de Bayes, un clásico con una buena relación rendimiento-resultados, y comenzamos la clasificación (Start). A la derecha podremos ver el resultado obtenido por el algoritmo elegido. Aunque hoy no vamos a entrar a analizar en detalle estos resultados, podemos ver que ha conseguido clasificar correctamente un 96% de las muestras de prueba. Esto nos indica que, teóricamente, ante nuevas muestras desconocidas, facilitando atributos como la longitud y anchura de pétalo y sépalo, seríamos capaces de conocer el tipo de Iris que correspondería. Y con esto acabamos una toma de contacto muy rápida con WEKA, una potente herramienta para el tratamiento y análisis de datos. Como decíamos, en próximas entregas iremos profundizando para conocer con más detalle la infinidad de opciones que ofrece. Por el momento, ya podemos empezar a entender cómo funcionan estos sistemas, una de las piezas claves de este siglo XXI, el siglo del flujo de información, el análisis de datos y el profiling de usuarios.


{kind=link}