


Como la gran mayoría de trabajadores de seguridad sabrá, hace varios meses se divulgó públicamente una vulnerabilidad conocida como «Dirty Cow» (CVE-2016-5195) que ha estado presente en el kernel de Linux desde la versión 2.6.22 de 2007 y, por lo tanto, presente en los sistemas operativos basados en Linux, incluyendo Android. Esto ha resultado en un toque de atención ya que, a pesar de todo el esfuerzo realizado por la comunidad para verificar y asegurar el kernel de Linux durante los últimos años, todavía se encuentran errores que conducen a vulnerabilidades críticas como ésta.
 En esta línea, un grupo de investigadores de la Universidad de Santa Barbara en California (UCSB) ha presentado un trabajo en la conferencia USENIX Security de este mismo año al que han denominado DR. CHECKER: A Soundy Analysis for Linux Kernel Drivers. En el artículo describen un estudio que ha dado lugar a una herramienta de búsqueda de errores para los controladores del kernel de Linux, la zona más propensa a errores como han demostrado previos estudios, identificando 158 errores 0-day en 9 kernels distintos de dispositivos móviles populares y sus controladores asociados. DR. CHECKER es una herramienta automática basada en análisis estático, que concretamente utiliza análisis de punteros y «taint analysis» (también conocido como seguimiento de flujo de información) de forma «flow-sensitive», «context-sensitive» y «field-sensitive» para obtener mejor precisión, lo que quiere decir que se tienen en cuenta el orden de las sentencias, la ubicación y secuencia de llamadas a funciones necesarias para alcanzar una determinada función y la capacidad de distinguir entre campos dentro de un objeto (como una estructura).
En esta línea, un grupo de investigadores de la Universidad de Santa Barbara en California (UCSB) ha presentado un trabajo en la conferencia USENIX Security de este mismo año al que han denominado DR. CHECKER: A Soundy Analysis for Linux Kernel Drivers. En el artículo describen un estudio que ha dado lugar a una herramienta de búsqueda de errores para los controladores del kernel de Linux, la zona más propensa a errores como han demostrado previos estudios, identificando 158 errores 0-day en 9 kernels distintos de dispositivos móviles populares y sus controladores asociados. DR. CHECKER es una herramienta automática basada en análisis estático, que concretamente utiliza análisis de punteros y «taint analysis» (también conocido como seguimiento de flujo de información) de forma «flow-sensitive», «context-sensitive» y «field-sensitive» para obtener mejor precisión, lo que quiere decir que se tienen en cuenta el orden de las sentencias, la ubicación y secuencia de llamadas a funciones necesarias para alcanzar una determinada función y la capacidad de distinguir entre campos dentro de un objeto (como una estructura).
El objetivo es que el análisis cumpla en la mayoría de lo posible con la propiedad de sólidez (soundness), no proporcionando falsos negativos. Sin embargo, para que el análisis sea práctico y escalable hacen 3 suposiciones:
- 1. Suponen que el código principal de Linux está perfectamente implementado y, por tanto, no se realiza análisis interprocedural en las llamadas a la API. Reduciendo el ámbito de esta forma sacrifican solidez para ganar precisión.
- 2. En los bucles sólo se realiza el número de recorridos necesarios para un análisis de definición de alcance (reach-def) en lugar de esperar a que converjan en un punto fijo, lo que puede llevar a que el análisis de punteros no cumpla con la propiedad de solidez.
- 3. Cada instrucción de llamada a función solo se recorre 1 vez incluso en los bucles, con el objetivo de limitar los falsos positivos a cambio de sacrificar solidez.
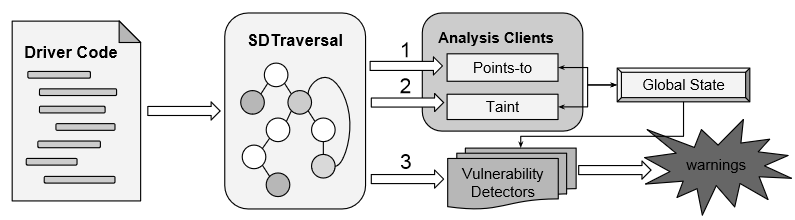
En el análisis, primero se recorre el código y se van invocando los distintos clientes de análisis (punteros y «taint analysis») en puntos específicos con el contexto y el estado global correspondientes. Todos los clientes de análisis utilizan y comparten el mismo estado global y por tanto se benefician de los resultados de todos ellos. Una vez se han ejecutado los análisis se aplican varios detectores de vulnerabilidades comunes, implementados como plugins, sobre los resultados para después poder generar advertencias. Los detectores implementados son los siguientes:
- 1. Usos inapropiados de «datos marcados». Comprueba si los «datos marcados» se utilizan en funciones peligrosas como strc* o sscanf.
- 2. Detector aritmético de «datos marcados». Comprueba usos de los «datos marcados» en operaciones que puedan causar un overflow o underflow.
- 3. Conversiones inválidas. Comprueba conversiones de un objeto a otro de distinto tamaño.
- 4. «Datos marcados» usados como límite en bucles.
- 5. Desreferencias de punteros «marcados». Cuando el usuario especifica un índice dentro de una estructura del kernel sin realizar comprobación.
- 6. Comprueba «datos marcados» que se utilizan como argumentos de tamaño en las funciones copy_to_ y copy_from_.
- 7. Detector de fugas provocadas por no inicializar.
- 8. Detector de carreras en variables globales. Concretamente variables globales que se acceden sin un «mutex».
Para la evaluación, han realizado un análisis sobre 9 kernels de dispositivos móviles populares con sus drivers correspondientes (437 en total) y, para tener una comparación, también han analizado los drivers usando otras herramientas de análisis estático (flawfinder, RATs, cppcheck y Sparse). DR. CHECKER supera a las herramientas mencionadas puesto que se trata de herramientas más simples no tan orientadas a la seguridad, requieren anotaciones manuales o fallan al detectar errores complejos. En total, DR. CHECKER encuentra 158 errores confirmados y genera 5.071 advertencias, de entre las cuales 3.973 resultan correctas (verificadas manualmente), lo que supone una precisión del 78%.
Por último, se evalúan las suposiciones planteadas al principio que permiten que DR. CHECKER sea práctico y escalable. Concretamente analizan 100 puntos de entrada escogidos aleatoriamente, lo que resulta en que solo 18 de los 100 análisis terminen en un intervalo de tiempo de 4 horas, generando un total de 63 advertencias tardando 52 minutos en evaluar, comparado a las 9 advertencias y 1 minuto de evaluación teniendo en cuenta las suposiciones. Por otra parte, también se evalúa la segunda suposición realizando análisis de punto fijo, resultando en mayor cantidad de advertencias. La evaluación de rendimiento se puede ver en la siguiente imagen.
DR. CHECKER se ha implementado como un módulo sobre LLVM 3.8 y se encuentra disponible en Github. Para operar necesita: un fichero bitcode (del driver), el nombre de la función de entrada y el tipo de la función de entrada.

