


En la anterior entrega sobre fuzzing explicamos a grandes rasgos los fundamentos principales y los distintos tipos que existen. En esta ocasión nos vamos a centrar en los frameworks de fuzzing, por lo que vamos a empezar por ver como es la estructura lógica general de un fuzzer, aunque no todos siguen el mismo modelo, se pueden distinguir los siguientes componentes genéricos:
- Modelado de datos: Es el elemento que describe (normalmente a través de gramáticas) el formato de los datos, la secuencia de mensajes o la estructura del protocolo que utilizará el componente de generación de datos.
- Generación de datos.: Haciendo uso de la información proporcionada por el modelado de datos, se encarga de construir los casos de prueba que servirán como entrada para el sistema objetivo.
- Motor de fuzzing: Encargado de la ejecución de los casos de prueba de entrada producidos sobre el objetivo.
- Supervisión y generación de informes: Responsable de supervisar el sistema que se está poniendo a prueba e informar de cualquier incidencia que se produzca. De esta forma se conoce el estado y el caso de prueba que ha desencadenado la incidencia.
AFL (American Fuzzy Lop) es un fuzzer orientado a seguridad que utiliza instrumentación en tiempo de compilación y algoritmos genéticos para mejorar la cobertura de código y descubrir automáticamente casos de prueba interesantes que desencadenen nuevos estados internos en el programa. Cuando el código fuente del objetivo está disponible, la instrumentación se realiza por una herramienta complementaria que provee AFL y funciona como un reemplazo para el compilador, tanto para gcc como clang. Por ejemplo, si quisiéramos usar el reemplazo de clang:
- $ CC=/ruta/a/afl/afl-clang ./configure; make clean all
Por otra parte, cuando el código fuente no está disponible AFL ofrece la posibilidad de instrumentar el binario a través de una versión de QEMU funcionando en modo emulador de espacio de usuario, implementando la instrumentación sobre los bloques básicos que utiliza QEMU en la traducción. Para utilizar esta característica se debe añadir -Q en la línea de comandos a la hora de ejecutar afl-fuzz, habiendo descargado, configurado y compilado QEMU previamente ejecutando el script /ruta/a/afl/qemu_mode/build_qemu_support.sh.
A grandes rasgos el algoritmo general de AFL se puede resumir en 6 pasos:
- 1. Cargar los casos de prueba proporcionados por el usuario en la cola.
- 2. Coger el siguiente fichero de entrada de la cola.
- 3. Intentar reducir el caso de prueba en la mayor medida de lo posible sin alterar el comportamiento calculado del programa.
- 4. Mutar repetidamente el fichero utilizando una variedad equilibrada de estrategias de fuzzing tradicionales.
- 5. Si alguna de las mutaciones generadas resulta en una nueva transición de estado registrada por la instrumentación, añadir dicha mutación como nueva entrada en la cola.
- 6. Volver a 2.
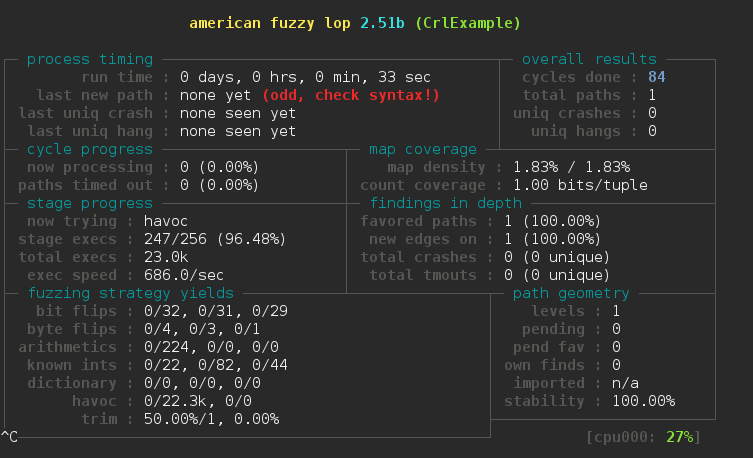 Para empezar con el fuzzing primero se necesita un directorio de lectura con un conjunto inicial de casos de prueba y otro directorio para guardar los descubrimientos. Una vez esté todo listo podemos empezar ejecutando (en caso de que el programa lea por la entrada estándar):
Para empezar con el fuzzing primero se necesita un directorio de lectura con un conjunto inicial de casos de prueba y otro directorio para guardar los descubrimientos. Una vez esté todo listo podemos empezar ejecutando (en caso de que el programa lea por la entrada estándar):
- $ afl-fuzz -i dir_entrada -o dir_descubrimientos /ruta/al/programa
Una vez en funcionamiento, se mostrará el estado del proceso en consola como se puede ver en la imagen.

