


En el campo de análisis de programas se emplean distintas técnicas que usualmente se dividen en dos grandes grupos: estáticas y dinámicas. El fuzzing o fuzz testing es una técnica dinámica utilizada ampliamente (sobre todo los últimos años) para descubrir bugs en software que, con un poco de (mala) suerte, podrían conducir a vulnerabilidades de seguridad. La idea principal detrás del fuzzing consiste en proporcionar datos inválidos o malformados como entrada de un sistema con el objetivo de desencadenar comportamientos inesperados, como un crash.
Para ilustrar el funcionamiento del fuzzing con un ejemplo muy simple, vamos a tomar como referencia el siguiente fragmento de código.
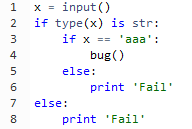 Como se puede ver, en la línea 4 se produce un bug cuando el valor de x contiene la cadena ‘aaa’, por lo tanto el objetivo consiste en proporcionar valores a x sucesivamente (i.e., ‘a’, ‘b’, …, ‘aa’, ‘ab’, …) hasta encontrar una entrada a partir de la cual se desencadene el bug y una vez descubierto, guardar todos los elementos necesarios para poder reproducirlo. La ventaja es que una vez que un fuzzer se pone en funcionamiento, se puede dejar durante días, semanas o meses en busca de errores sin necesidad de interacción.
Como se puede ver, en la línea 4 se produce un bug cuando el valor de x contiene la cadena ‘aaa’, por lo tanto el objetivo consiste en proporcionar valores a x sucesivamente (i.e., ‘a’, ‘b’, …, ‘aa’, ‘ab’, …) hasta encontrar una entrada a partir de la cual se desencadene el bug y una vez descubierto, guardar todos los elementos necesarios para poder reproducirlo. La ventaja es que una vez que un fuzzer se pone en funcionamiento, se puede dejar durante días, semanas o meses en busca de errores sin necesidad de interacción.
Cabe destacar que, para un fuzzing efectivo, los datos de entrada proporcionados no deben ser simplemente malformados o aleatorios, sino que deben ser suficientemente válidos como para superar pruebas elementales de consistencia y no ser directamente rechazados, pero suficientemente excepcionales como para producir comportamientos inesperados. Dependiendo de como se crean los datos de entrada, se distinguen 3 tipos de fuzzing: los basados en mutaciones que crean los datos de entrada mutando «aleatoriamente» valores de entrada válidos, los basados en generación que generan los datos de entrada desde cero y el fuzzing evolutivo, que a partir de un conjunto de valores iniciales de entrada y utilizando un algoritmo evolutivo produce los valores que mejor se adaptan en base a una serie de propiedades.
Por otra parte, dependiendo del conocimiento del fuzzer sobre el formato de los valores de entrada, se distinguen 2 tipos: el dumb fuzzing, que como su nombre indica no necesita ningún conocimiento sobre el objetivo y el smart fuzzing, que es consciente de la estructura de entrada a través de modelos o grámaticas. La principal diferencia entre ambos tipos es la validez de los valores de entrada y la cantidad de trabajo necesario para generarlos, es decir, un dumb fuzzer generará casos de prueba con menos esfuerzo que un smart fuzzer pero la proporción de entradas válidas (casi) siempre será menor.
Actualmente el fuzzing es un área activa de investigación debido a su efectividad y buenos resultados, lo que también ha favorecido que las empresas lo adopten dentro del proceso de verificación de calidad en el ciclo de vida de desarrollo de software. Como muestra de su efectividad, Google anunció hace varios meses que su proyecto OSS-Fuzz había encontrado más de 1.000 bugs en 47 proyectos distintos de código abierto en un plazo de 5 meses.

