


Uno de los puntos donde más se suele utilizar el análisis de los datos es en el ámbito de los servidores. Existen multitud de herramientas para realizar este análisis, pero en este caso vamos a utilizar de nuevo las herramientas que nos permitió adivinar si un viajero del Titanic iba a sobrevivir o no a la catastrofe. Para ello, necesitamos un log para poder analizar. En este caso, hemos optado por una parte del log de la herramienta DukeCapture. En concreto, el log se encuentra en la dirección https://web.duke.edu/its/programInformation/DukeCapture/logs/u_ex120301.log.
Empezemos el análisis.
%pylab inline Populating the interactive namespace from numpy and matplotlib
Indicamos la ruta la fichero de log.
log_path = r'./log'
Añadimos los imports necesarios. En concreto utilizamos las librerías de numpy y pandas, del sistema operativo; matplotlib para poder obtener gráficas y finalmente, seaborn, que mejora el aspecto visual de matplotlib.
import pandas as pd import numpy as np import os import matplotlib.pyplot as plt import seaborn
Preprocesado del fichero
Leemos todos los ficheros de log, y todas las entradas, eliminando todas aquellas que sean comentarios.
def parse_logs(path):
logs = []
for file in os.listdir(path):
if file.endswith(".log"):
# First, we read all the lines of the file, excluding the coments
file = [x.split(' ') for x in open(path + '/' + file).readlines()
if x[0] is not '#']
# We append the files
logs += file
return logs
logs = parse_logs(log_path)
Cargamos el fichero en un DataFrame de Pandas
df = pd.DataFrame(logs)
Cambiamos el nombre de las columnas para que sea más legible
df.columns = ['date',
'time',
's-ip',
'cs-method',
'cs-uri-stem',
'cs-uri-query',
's-port',
'cs-username',
'c-ip',
'cs(User-Agent)',
'sc-status',
'sc-substatus',
'sc-win32-status',
'time-taken']
Ahora, convertimos combinamos la fecha y la hora, y lo sustituimos en el dataFrame.
df.insert(0, 'datetime', pd.to_datetime(df.apply(lambda x: x['date'] + ' ' + x['time'], 1)))
df = df.drop(['date', 'time'], 1)
# Creamos un índice con el tiempo
df.index = df['datetime']
df.drop('datetime',1)
| s-ip | cs-method | cs-uri-stem | cs-uri-query | s-port | cs-username | c-ip | cs(User-Agent) | sc-status | sc-substatus | sc-win32-status | time-taken | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| datetime | ||||||||||||
| 2012-03-01 00:00:00 | 152.3.102.77 | POST | /Panopto/Services/RemoteRecorder.svc | – | 80 | – | 152.3.113.150 | – | 200 | 0 | 0 | 78\n |
| 2012-03-01 00:00:00 | 152.3.102.77 | POST | /Panopto/Services/RemoteRecorder.svc | – | 80 | – | 152.3.137.194 | – | 200 | 0 | 0 | 31\n |
| 2012-03-01 00:00:00 | 152.3.102.77 | POST | /Panopto/Services/UploadTracker.svc | – | 80 | – | 152.3.102.77 | – | 200 | 0 | 0 | 15\n |
| 2012-03-01 00:00:00 | 152.3.102.77 | POST | /Panopto/Services/Recorder.asmx | – | 80 | 00000004:win.duke.edu\jlv11 | 152.3.41.226 | Mozilla/4.0+(compatible;+MSIE+6.0;+MS+Web+Serv… | 200 | 0 | 0 | 437\n |
| 2012-03-01 00:00:00 | 152.3.102.77 | POST | /Panopto/Services/Recorder.asmx | – | 80 | 00000005:avws2 | 152.3.161.68 | Mozilla/4.0+(compatible;+MSIE+6.0;+MS+Web+Serv… | 200 | 0 | 0 | 234\n |
| 2012-03-01 00:00:00 | 152.3.102.77 | POST | /Panopto/Services/RemoteRecorder.svc | – | 80 | – | 152.3.157.149 | – | 200 | 0 | 0 | 46\n |
| 2012-03-01 00:00:00 | 152.3.102.77 | POST | /Panopto/Services/RemoteRecorder.svc | – | 80 | – | 152.3.113.150 | – | 200 | 0 | 0 | 265\n |
Y vemos de un primer vistazo los datos.
df.describe()
| datetime | s-ip | cs-method | cs-uri-stem | cs-uri-query | s-port | cs-username | c-ip | cs(User-Agent) | sc-status | sc-substatus | sc-win32-status | time-taken | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 22404 | 22404 | 22404 | 22404 | 22404 | 22404 | 22404 | 22404 | 22404 | 22404 | 22404 | 22404 | 22404 |
| unique | 706 | 1 | 3 | 387 | 281 | 2 | 15 | 147 | 23 | 6 | 1 | 2 | 141 |
| top | 2012-03-01 00:11:05 | 152.3.102.77 | POST | /Panopto/Services/RemoteRecorder.svc | – | 80 | – | 152.3.41.226 | – | 200 | 0 | 0 | 15\n |
| freq | 128 | 22404 | 21493 | 9325 | 22085 | 22379 | 21589 | 5122 | 20917 | 17852 | 22404 | 22387 | 4554 |
| first | 2012-03-01 00:00:00 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| last | 2012-03-01 00:12:08 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
Análisis de tiempos
En primer lugar, vamos a analizar la frecuencia con la que el serividor recibe peticiones.
# Nos quedamos con la columna de tiempo
datetimeDF = df.ix[0:, ['datetime']]
server_times = []
for i, row in datetimeDF.iterrows():
server_times.append(row['datetime'])
# Y ordenamos la lista
server_times.sort()
time_until_next = []
for i in xrange(1, len(server_times) - 1):
time_diff = (server_times[i] - server_times[i-1]).seconds
time_until_next.append(time_diff)
Creamos el histograma inicial
time_to_next_series = pd.Series(time_until_next) time_to_next_series.hist(normed=True)
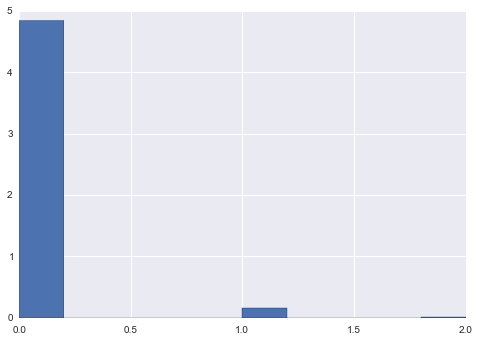
<matplotlib.axes._subplots.AxesSubplot at 0x97bcb00>
Análisis de las IPs
A continuación, analizamos la información de las IPs desde las que se conectan.
Para ello, primero agrupamos las IPs y calculamos cuantas peticiones hay de cada IP.
ip = df.groupby('c-ip').size()
Analicemos ahora las 10 que más visitan.
ip.sort() ip[-10:].plot(kind='barh')
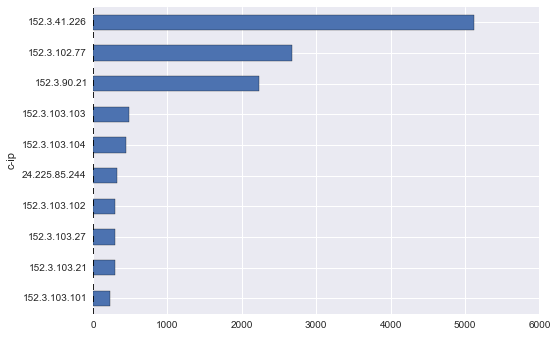
<matplotlib.axes._subplots.AxesSubplot at 0x78abac8>
Análisis de las respuestas
A continuación se obtienen datos de los distintos tipos de respuestas posibles. Creamos un DataFrame para cada uno de los tipos de error que contemplamos. También vamos a hacer un resample, con una frecuencia de «5t», es decir, por cada 5 muestras de tiempo t se genera una.
# Convertimos la columna a columna de ints
df['sc-status'] = df['sc-status'].astype(int)
t_span = '5t'
df_404 = df['sc-status'][df['sc-status'] == 404].resample(t_span, how='count')
df_403 = df['sc-status'][df['sc-status'] == 403].resample(t_span, how='count')
df_301 = df['sc-status'][df['sc-status'] == 301].resample(t_span, how='count')
df_302 = df['sc-status'][df['sc-status'] == 302].resample(t_span, how='count')
df_304 = df['sc-status'][df['sc-status'] == 304].resample(t_span, how='count')
df_200 = df['sc-status'][df['sc-status'] == 200].resample(t_span, how='count')
status_df = pd.DataFrame({'Not Found':df_404, 'Forbidden':df_403, 'Moved Permanently':df_301, 'Moved Temporaly': df_302, 'Not Modified':df_304, 'OK':df_200})
status_df
| Forbidden | Moved Permanently | Moved Temporaly | Not Found | Not Modified | OK | |
|---|---|---|---|---|---|---|
| datetime | ||||||
| 2012-03-01 00:00:00 | NaN | 63 | 108 | NaN | 11 | 7492 |
| 2012-03-01 00:05:00 | NaN | NaN | 98 | NaN | 24 | 7115 |
| 2012-03-01 00:10:00 | NaN | NaN | 2 | NaN | NaN | 3245 |
Normalizamos los datos a 1 para ver el gráfico de forma más clara
normed_subset = status_df[['OK','Moved Temporaly']].div(status_df[['OK','Moved Temporaly']].sum(1), axis = 0) normed_subset.plot(kind='barh', stacked=True)
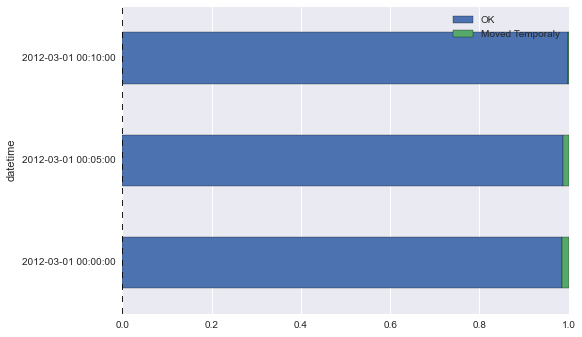
<matplotlib.axes._subplots.AxesSubplot at 0xc284a58>
Esto es sólo un pequeño ejemplo de las cosas que se pueden hacer con este tipo de herramientas.
Ahora os toca a vosotros jugar con vuestros logs y empezar a analizarlos.

